


GeoAI Unpacked #3: Evolution of Geospatial Data ETL & Analytics

Welcome to GeoAI Unpacked! I am Ali Ahmadalipour and in this newsletter, I share insights and deep dives in geospatial AI, focusing on business opportunities and industry challenges. Each issue highlights key advances, real-world applications, and my personal takeaways on emerging opportunities. For a sneak peak at the topics I plan to cover in upcoming issues, visit here.
In this issue, I’ve delved into geospatial data ETL (Extract, Transform, Load) and its evolution over the past few decades. We’ll explore the ecosystem, opportunities, and challenges shaping this space. Let’s dive in!
1. The basics - geospatial data types
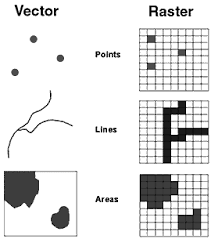
Geospatial data fundamentally falls into two categories:
Vector data: This type represents geographical features using geometric shapes such as points, lines, and polygons. Think of it like a digital drawing, where each element is a distinct object. Points can mark specific locations (e.g., weather stations), lines represent linear features (e.g., roads, rivers), and polygons define areas (e.g., countries, lakes).
Raster data: This format divides the Earth's surface into a grid of cells, similar to a photograph. Each cell holds a value that corresponds to the area it covers, creating a continuous surface. This value could represent elevation, temperature, land cover, or any other measurable variable.
These formats serve distinct analytical needs and can be interconverted. For instance, point data for observed temperatures can be transformed into a gridded raster dataset using interpolation techniques, which allows a more comprehensive understanding of temperature patterns. Conversely, raster data can be converted into vector data to extract specific features or boundaries for analysis. Vector data is also commonly used to define administrative boundaries, like countries or states, which helps focusing analysis on specific areas of interest.
2. Traditional GIS
Prior to the widespread adoption of the internet and even into the early 2010s, geospatial workflows were largely conducted on-premise (primarily a desktop affair). Data was downloaded and processed locally, placing significant emphasis on hardware capabilities. This necessitated careful consideration of the following factors to ensure feasibility and efficiency:
Storage —> Disk space to accommodate the often-large datasets
Internet Bandwidth —> for data transfer and download
Memory (RAM) —> to handle the processing demands of the analysis
Compute (CPU) —> processing power to perform the required analyses
These constraints often led to a focus on file formats that minimized storage requirements, even if those formats were not always user-friendly or easily understood. Specialized tools and software emerged to handle these file formats. Esri's ArcGIS has been a dominant force in the GIS software landscape for decades, and its high cost has spurred the development of open-source alternatives like QGIS and ILWIS, providing accessible options for individuals and smaller organizations. While Esri has evolved into much more than just a software vendor (with a diverse portfolio of products and services and a global presence), startups continue to take on the formidable task of challenging its market dominance. For a deeper dive into Esri's history, Joe Morrison's blog post offers valuable insights.
Traditionally, shapefiles (.shp and its associated files: .shx, .dbf, .prj, .kml) were a common format for storing vector data. Raster data, such as satellite imagery, was typically stored in formats like GeoTIFF or HDF, often as individual tiles for different regions and dates. Moreover, gridded datasets, such as weather observation data, were frequently stored in formats like GRIB or binary files, which are notoriously difficult to work with. Specialized software like MATLAB or open-source options like R and NCL were utilized for analyzing these gridded data. Then there was GDAL, an open-source library that became a lifesaver for reading and writing raster and vector formats, earning a special place in the geospatial toolbox for data transformation. Despite the advancements in modern geospatial technology, these older formats are still employed.
The complexity of the software and the specific requirements of each file format presented significant barriers to entry into the geospatial field and made geospatial analysis a specialized niche requiring significant expertise to get started with. Additionally, most analyses were confined to regional scales due to the limitations in computational power and processing capacity. Large-scale analysis of datasets like satellite imagery or climate data was primarily the domain of national labs and government agencies with access to supercomputing resources, and even for them, processing times were substantial.
3. Modern geospatial
Recent years have witnessed significant advancements in geospatial analysis and data ETL. The emergence of cloud computing and cloud-native geospatial tools, coupled with the evolution of data formats and the rise of open-source software like Python, has revolutionized the landscape of geospatial workloads. This transformation is evident even in the evolution of industry giants like ESRI, which has developed a suite of products for geospatial cloud and ArcGIS Online.
3.1. Cloud native geospatial data
Modern geospatial data management has shifted towards cloud-centric solutions. Formats like Cloud-Optimized GeoTIFF (COG) and Zarr have been developed for raster and gridded datasets, while GeoParquet serves as a columnar storage format for vector data. These formats enable direct access without the overhead of downloading. In recent years, major cloud providers and database platforms—such as Google Bigquery, AWS Athena, Microsoft Azure Cosmos DB, MangoDB, and SnowFlake—have introduced spatial query functionalities, including support for Spatial SQL. These capabilities allow users to process GeoJSON (and in some cases, GeoParquet files), enabling operations like spatial joins and intersections, which are invaluable for geospatial analysis.
Users often no longer need to download data to their own storage / repository before working with it. Instead, data can be pre-processed directly in the cloud. I had developed a tutorial using XEE—a Python library that integrates Google Earth Engine (GEE) with Xarray—to demonstrate a simple example of such workflows. Efficient data access is crucial in this context. Spatial and temporal indexing have become paramount, leading to the development of tools like the SpatioTemporal Asset Catalog (STAC) which aims to provide a standardized framework for describing and cataloging spatiotemporal assets.
3.2. Cloud-Native Geospatial Analytics
Modern geospatial computing has undergone a significant transformation, driven by the rise of cloud computing technologies. Geospatial services are increasingly adopting cloud-native architectures. This involves leveraging cloud-specific services like:
Microservices: Breaking down complex applications into smaller, independently deployable services. This improves scalability, resilience, and maintainability.
Serverless functions: Executing code on-demand without the need to manage servers. This reduces operational overhead and allows for cost-effective scaling based on actual usage.
Containerization (e.g. Docker or Kubernetes): Packaging applications and their dependencies into containers, ensuring consistent deployment across different environments.
The above combination enables on-demand scaling, optimized resource utilization, and reduced operational overhead, making it ideal for handling the often-large datasets and computationally intensive tasks associated with geospatial analysis.
4. Ecosystem and marketplace
The geospatial industry can be viewed as having distinct layers: core platform providers and application developers. Core developers provide foundational tools for data management, mapping/visualization, and analytics. A larger group of companies then leverage these core tools to create specific applications and products, such as flood forecasting and crop type mapping. This article focuses specifically on companies providing foundational geospatial platforms and core tools. For a broader overview of companies engaged in various geospatial analytics and applications, check out this curated list of over 300 companies.
Here, I have categorized the geospatial data ETL ecosystem into three main sectors: government-related entities, big tech, and startups.
4.1. Government-related geospatial entities
This sector encompasses government agencies and their associated contractors, often characterized by significant budgets and a degree of operational secrecy. The National Geospatial-Intelligence Agency (NGA) in the United States serves as a prominent example. While NGA's annual budget is classified, leaked documents from 2013 indicated an expenditure of about $5 billion per year.
A handful of prominent companies that operate in this space are: Booz Allen Hamilton, Lockheed Martin, Leidos, Palantir, and ESRI. The scale of funding for their contracts is immense, underscoring the importance of geospatial capabilities in defense, intelligence, and national security. Here are a few examples of significant contracts awarded by NGA to these companies in recent years:
$900M (May 2023) to 13 companies including Booz Allen Hamilton & Leidos
$794M (Jan 2024) to Booz Allen Hamilton, Lockheed Martin, Reinventing Geospatial, and Solis Applied Science
$290M (Sep 2024) to 10 companies including Booz Allen Hamilton
$245M (Oct 2018) to Booz Allen Hamilton + $52M extension (Sep 2023)
$107M (Dec 2024) to Leidos
$56M (Mar 2024) to ESRI
4.2. Big Tech and Geospatial data ETL
Big Tech's entry into the geospatial data ETL market was catalyzed by Google's introduction of Earth Engine in 2010, a cloud-based platform for planetary-scale geospatial analysis. This groundbreaking initiative, coupled with the publication of a seminal paper in 2013 garnered significant attention and paved the way for other tech giants to enter the space. Microsoft (with its Planetary Computer), Amazon (through AWS offerings such as Amazon Earth and various geospatial services), and IBM (with its Environmental Intelligence platform) recognized the potential and entered the arena too. Although as of June 2024, Microsoft retired the Planetary Computer Hub—which offered computing and application capabilities—while continuing to maintain the Data and APIs.
While the above companies have taken a leading role, other major players like Oracle, SnowFlake, DataBricks, and MangoDB also provide relevant services, through integrating geospatial capabilities into their broader offerings for enterprise solutions and database management. Furthermore, location-driven businesses like Uber have significantly contributed to innovation in this area, developing solutions like the H3 spatial indexing system for efficient geospatial data partitioning and analysis.
4.3. The startup landscape
The geospatial data ETL marketplace is vibrant, with startups pushing boundaries across various domains. These companies are developing innovative tools and platforms to streamline data ingestion, processing, visualization, and analysis. It’s important to note that the categories are broadly assigned and many of these companies operate across multiple groups, reflecting the interconnected nature of the geospatial ecosystem. Here are some key areas where geospatial data ETL startups are making an impact:
Location intelligence: Foursquare, Carto, Mapbox, SafeGraph
Data management / processing: DuckDB, Wherobots, Earthmover, Fused, Coiled
Visualization / mapping: Tableau, Unfolded (acquired by Foursquare), Felt, Mapular
Data platforms: Orbital Insight (acquired by Privateer), Descartes Labs & GeoSite (both acquired by EarthDaily Analytics), Cecil
This dynamic landscape reflects the evolving needs of the market and the increasing demand for comprehensive geospatial data solutions.
5. Challenges of geospatial data ETL
Geospatial data ETL presents a unique set of challenges compared to traditional data ETL processes. These challenges stem from the inherent complexity of spatial data, its often large size, and the diverse formats and systems involved.

5.1. No one-size-fits-all solution
One of the primary challenges is the lack of a universal solution that balances cost, performance, and flexibility/customizability. Off-the-shelf ETL tools may not adequately handle the specific requirements of geospatial data, such as complex geometric operations or specialized spatial attributes. Conversely, building a completely custom solution can be expensive and time-consuming. Finding the right balance between using existing tools, custom scripting, and cloud-based services is crucial and often requires careful consideration of project needs and resources.
5.2. Handling large datasets
Geospatial data often arrives in truly massive quantities—think petabytes of satellite imagery, billions of LiDAR points, or intricate high-resolution vector layers. This sheer volume presents a formidable challenge for ETL processes. Effectively managing this data deluge requires robust strategies for scalability, efficient storage solutions that don't break, and powerful compute resources capable of crunching through these massive datasets without grinding to a halt.
5.3. Data quality and standardization
A significant hurdle in geospatial ETL is ensuring data quality and consistency. Geospatial data originates from diverse sources, each with varying collection methods, accuracy levels, and schemas. This necessitates robust data cleaning, validation, and harmonization processes to address issues like missing data, inconsistent attributes, and geometric errors.
5.4. Interoperability between platforms and formats
The geospatial world is characterized by a multitude of data formats, including GeoTIFF, Shapefile, hdf, and NetCDF, among others. Ensuring seamless interoperability between these formats is crucial for efficient data processing and analysis. This often requires data conversion and transformation steps, which can be time-consuming and error-prone.
5.5. Spatiotemporal challenges of API Design
Designing APIs for geospatial products can quickly become complex due to the inherent spatiotemporal challenges. Consider this scenario: downscaled climate models are freely available on the cloud, and you aim to develop a product that extracts climate change insights from those data. while this may seem straightforward and lucrative, diverse use cases demand significantly different API designs. Here are a few examples:
Point-based queries: Delivering yearly precipitation change for specific locations within a particular decade
Area-based queries: Assessing monthly temperature change for a defined area (a rectangular box)
Polygon-based queries: Analyzing growing degree days for a farm with an irregular boundary (not limited to rectangles)
Sub-daily, multi-region, time-series analysis: Quantifying changes in chill hours in the early growing season across farms in different parts of the world (with varying growing season months)
Multivariate global analysis: Identifying locations worldwide with optimal climate conditions (based on multiple variables) for specific crops during their respective growing seasons
Beyond these spatial and temporal varying requirements, several other factors must be considered such as:
Scalability —> Handling varying number of locations/areas per API call
Flexibility —> Supporting diverse models, scenarios, and time periods of interest
Output options —> Catering to both spatial mean and granular spatial outputs
Given constraints on latency and cost (for storage and compute), designing a robust and efficient backend architecture to handle these complexities presents a substantial challenge.
5.6. Coordinate Systems and Transformations
Working with diverse Coordinate Reference Systems (CRS) is another significant challenge in geospatial ETL. Differences in CRS can lead to spatial misalignments, errors in distance or area calculations, and difficulties in integrating datasets from different sources. Transforming data between CRSs is computationally intensive and can introduce errors, especially when working with large or highly precise datasets.
The above challenges illustrate the intricate nature of geospatial data ETL, where each step requires careful consideration to ensure efficiency, accuracy, and interoperability. Addressing these issues presents significant business opportunities, and many startups have emerged with innovative solutions tailored to tackle these complexities.
6. Final remarks
Over the past years, geospatial data ETL and analytics have advanced significantly, with innovations in cloud-native tools, data formats, and processing frameworks transforming the landscape. However, there is still considerable room for improvement, particularly in geospatial machine learning, where combining spatial and temporal features remains a complex challenge. Developing no-code or low-code tools can simplify access to data and analytics capabilities, enabling a broader audience to engage with geospatial modeling. By democratizing these technologies, we can make geospatial insights more accessible and empower more people to harness the power of spatial data for solving real-world problems.
❗️ As a reminder, this article is for general knowledge and informational purposes only. It does not constitute financial or other professional advice.
Hi Ali, this is a very wonderful summary of the evolution and geo-industry. I am a geospatial engineer/research scientist who deals with all thing part 3-5. I hope to collaborate sometime in the future.